
. Introduction
The problem of determining the regression model parameters is already resolved and described in numerous literary positions: from basic, purely theoretical (Rao et al., 2008; Sen and Srivastava, 1994) through application descriptions (e.g., Vecchia (1988); Weisberg (1980)) up to summarising positions (Glumac and Des Rosiers, 2018; Manly and Alberto, 2016; McCluskey and Borst, 2017). Against the background of this literature, the question of applying a regression analysis to the real property valuation is also seen as a well-explored field. Because of the big number of the literature reference items, only a few of them are listed: Albritton (1982); d’Amato and Kauko (2017); Bruce and Sundell (1977); French (2003, 2004); Isakson (1986); McCluskey and Borst (1997 McCluskey and Borst (2017); Pagourtzi et al. (2003); Peto et al. (1996); Schlaes (1984); Shenkel and Eidson (1971); Skaff (1975); Tchira (1979); Thompson and Gordon (1987). Despite the extensive writing base in this area, there is very little attention paid to the question of the sold properties similarity. In addition to the very local voices of valuation practitioners, only in a few and rather old scientific publications, for example, Shenkel and Eidson (1971); Skaff (1975); Tchira (1979) or Czaja (1997), there were comments on the comparative objects’ selection based on their mutual likeness. At the heart of these concepts was the collection of objects perhaps few, but in a certain way similar to the valued property. Today’s trends in the development of real estate valuation methodologies indicate the advantage of the method of developing data over the original information and its usefulness for specific valuations. The issue of similarity is the subject of less and less attention. In some areas of the economy (mainly banking, taxes), econometric techniques as overarching techniques are recommended. This is contrary to the regulations of many professional associations (International Valuation Standards Council (IVSC), 2010; Royal Institution of Chartered Surveyors (RICS), 2017; Standards’ Commision of Polish Federation of Valuer’s Associations (SCPFVA), 2009) but also to direct legal directives (Bundesministerium für Umwelt Naturschutz Bau und Reaktorsicherheit (BMUB), 2006; ImmoWertV, 2009; Act, 1997; Regulation, 2004). Aims of this paper are: to direct attention again to the role of similarity seen as a factor, that can define the scope of real estate (or land) property local market and to demonstrate relationship between a similarity degree of collected comparables and undertaken estimations accuracy.
. Property value model
The linear price model consists of several structural parameters xj and corresponding observations of sale subject features aij. Combinations of those components juxtaposed with the sale prices yi create a price model equation (1).
where:i = 1, 2, . . . , n i ∈ N, where n is a number of observations yA,
j = 1, 2, . . . , k j ∈ N, where k is a number of structural parameters xA,
ai0 = 1.
Same number of such equations can be expressed as the system in matrix form (2). The solution for the system (2) of observations YA and A is given (according to the Gauss-Markov Theorem) as the best linear unbiased estimator of structural parameters
To emphasize the relationship between specific Y and X vectors, expressed in the dimensions of matrix A: n i k, complementary markings in indexes were added in the following equations. This issue is important when, by selecting elements yi and the consistent need of elimination of some independent variables, aij too poorly correlated with the vector yi, the shape of matrix A itself also changes.
Elements εAi, collected in vector ε A, are stochastic components of each i-th equation.
On the field of property valuation the variable YA, can be understood as the vector of sold property prices yAi (usually recalculated into proper surface unit prices), while the matrix A is the set of market feature evaluations, recorded while the survey of comparable properties.
The vector of price observations YA, market feature evaluations set A with a set of listed attributes ΨA, create together an information system (5) defined by Pawlak (1981, 1983) as:
where:YA is the set of price observations,
Ψ A is the list of attributes (market features), in (2) each element of Ψ A has its own value shown in XA,
Va is the set of all possible values of attributes (market features),
a(y, x) are values of attributes, relationship between YA and Ψ A, such YA × Ψ A → A.
In this paper, for short, it will be presented as:
The system (5) also represents a common price/value model (2) used to obtain econometric models of the property value (Pagourtzi et al., 2003). In a practice of econometrics, the main goal of the use of regression models is to find the model itself or to confirm the significance of its several listed parameters. In an appraisal practice (based on the econometrics anyway), the prediction of values of some properties is the most important.
The prediction of the value
As well as the value prediction itself, an accuracy of the obtained estimation results and being sure of appropriation of them are essential in appraising activity.
Statistical techniques of LSM gives some solutions regarding how to test the obtained model. The useful parameters are: the residual variance S2 of the model, presented in equation (8) as
n is number of observations yA and rows number of YA,
k is number of structural parameters xA and k + 1 is a columns number of A,
Above indicators are not enough for the valuation purpose, because they give information about the statistical evaluation of a used model only, without any judgement, if this model is good enough for the valuation of the exact object (even if the object is within the scope of the limitations of the considered local market). This question can be solved with indicators connected with the valuation object. For example, with ex ante indicators: like the residual variance
But the strongest verification of each value prediction is the ex post juxtaposition of the obtained result with the independent price eventually created by the market. Therefore, ‘the accuracy’, mentioned in the title, will be understood in further considerations as an ex post prediction error Q, defined as the difference between the ‘true’ or ‘real’ value YVR and the predicted value
. The research problem outline
The goal of much statistical modelling is to investigate the relationship between a criterion (dependent) variable and a set predictor (independent) variables. But for a number of studies related to the modelling of property prices on the selected local market, the primary objective remains to predict the price for the next element of the market. The more properties defining the local market are similar to the valued element (the appraisal subject), the more undertaken prediction is convincing. This evaluation might be weak from a statistical point of view. But when the valued element is close to the nearest sold properties (via their feature evaluations), their sales prices are the best data to predict anything among them.
Therefore, in this type of real estate modelling applications, it is important to emphasize the mutual similarity factor. Its presence in the price model was proved in Zyga (2016 in Zyga (2019). On the other hand, this study focuses on the importance of the similarity criterion for the price model construction. The valued object was considered a benchmark for assessing this similarity.
To make the problem easier to describe, a dissimilarity factor is used in the next steps. The difference (dissimilarity) di,j, between the ai,j element of the set A and the proper fV1,j element of set FV describing the subject of the valuation is defined as:
where:ai,j is the i, j element of matrix A,
i = 1, 2, . . . , n, i ∈ ℕ, where n is a number of observations yA,
j = 0, 1, 2 . . . , k, j ∈ ℕ, where k is a number of structural parameters xA,
ai0 = 1,
fV1,j is the j element of the single-line matrix of the FV pattern.
For the whole set of data, we obtain respectively:
where:DA is the matrix of dissimilarity (the differences matrix) between the sold properties with evaluations collected in matrix A and the appraised property; dimensions in rows and columns (n × k);
FV is the vector comprising evaluation marks given to the appraised property; it is the single-line matrix with dimensions (1 × k);
[1] is the vector of elements equal to 1; dimensions in rows x columns (n × 1).
The small example of DA matrix creating is shown in equation (18) (the juxtaposition of the assumed matrix A, the multipicated pattern single-line matrix FV (FV = [4 1 5 1]), and the dissimilarity matrix DA). Matrices are set in the same order as in (17).
(18)
Putting (17) in (7) gives us a solution for
The equation (19) can be easily modified back to the equation (7) because modification (19) does not bias the solution in any way. But it shows how the dissimilarity factor works within this structure and proves that the connections between the dissimilarity and the final effect of estimation in the LS method really exist. The matrix DA gives the possibility of easy selection from the whole collected set of comparables (YA, A), such as sales prices yAi with proper subsets of market feature evaluations aij (recorded in proper rows of matrix A) that their dissimilarity indicators (16) are the lowest. This step creates a smaller set of selected comparables (YA, A). By reducing the row number of matrix A, the variability of variables represented by individual columns of A is inevitably limited. This, in turn, forces the rejection of these variables from XA as too poorly correlated with the new vector YA. This reduction is the last step in modifying of selected comparables and gives finally new shape of data set still named (YA, A) but with reduced n as a number of observations and new k as a number of properly significant variables.
The reduction of initially collected set of comparables (YA, A) must be supervised under assumed criterion indicators. Dissimilarity di,j of j-th component of i-th comparable object description and the proper elements of benchmark evaluation vector FV can be accepted when
where:i = 1, 2, . . . , ninitial, i ∈ ℕ, where ninitial is a number of initially collected observations yA,
j = 0, 1, 2, . . . , kinitial, j ∈ ℕ, where kinitial is a number of initially defined structural parameters xA,
Kmax ∈ (0, 1〉 and is a number assumed by the tester for sub-sequent tests.
To calculate dmaxj, a certain criterion value Kmax assumed by the tester for each tests is needed. It can take values from 0 to 1 and creates the upper limit of accepted dissimilarities di,j.
In a similar way, a correlation between modified vectors A〈j〉 and modified YA must be controlled afterwards. For this purpose, a next criterion indicator is used. This indicator Kcorrmin is a declared minimum limit of accepted correlation rYA,Aj, so:
where:cov (YA, A〈j〉) is a covariance between indicated variables,
σ– is standard deviation operator of selected variable, Kcorrmin ∈ (0, 1〉 and is a number assumed by the tester for subsequent tests.
Technically, Kcorrmin can take values greater than 0 up to 1, but for practical use, it should be greater than 0.2 or even 0.3. On other side, it should not be greater than 0.5. Under real estate circumstances, the forcing of solutions based on the strong correlations (Kcorrmin greater than 0.5) can create empty sets of the reduced matrix A with no real answer about significance of any predictor variables. In the tests carried out and described below, Kcorrmin values were assumed in the range from 0.05 up to 0.6 in order to test the margin results also.
. Simulation experiment
The effect of the new parameter, which is Kmax criterion, on the selection of the set of initially collected records (YA, A) and on the accuracy of estimates made with the use of such (limited) subsets, have been tested in the experiments described below. In several experiments, reduced sets of comparable properties, collected separately for each final appraisal, included properties described by the condition (20) with respect to (21).
The accuracy of the obtained estimations was evaluated by the difference Q (14) between the response value
To illustrate a possible variability of the price estimator results on the performed property market, the artificial (simulated) picture of some local market was taken into account. Simulated market (it was demonstrated earlier in (Zyga, 2019)) was represented by 104 real properties randomly drawn from 625 = 54 possible records (because of 4 features described by marks from 1 to 5). Each simulated object had its own set of feature marks (without any detailed description). Although real estate attributes are usually qualitative variables (measured on ordinal scale), in the experiment, simulated marks can be understood as measurements of several attributes made of interval scale.
Each simulated property was priced as YA = AXA and biased with ε A, accordingly to (2). Errors ε A were specified randomly with an assumed margin of standard deviation: E(ER) = 0.000, max(ER) = 0.593, min(ER) = –0.620, std(ER) = 0.200, ε Ai = (1 + ERi)AXA.
True (modelled) values of the above properties were calculated simultaneously as (23).
With this data, each from 104 simulated properties was appraised, but not once. The performed market was analysed each time, whether it was similar enough for each property that was to be appraised. Each appraisal was performed several times, with each assumed values of Kmax and Kcorrmin. At least 16014 single experiments were performed.
Kmax was a criterion factor affecting the accepted maximum dissimilarity represented by the distance dmaxj (21) between the compared properties (each comparable and appraised one). In each appraisal process, Kmax limited a selection set of accepted (enough similar) comparables taken to the next steps of the process, accordingly to the rule (20). Kmax varied from 0.25 to 1.00. For technical reasons and the expected number of tests, the Kmax-values were assumed at the fixed interval of 0.05. Afterwards, the results themselves have been arranged in three ranges of values, that one can see on Figure 1. This provides an indirect evidence that, with limited variability in the value of the aij, there was no need to take a smaller jump of the tested Kmax. Values Kmax ∈ 〈0.25, 0.45〉 created a sharp criterion of dissimilarity, that forced the selection of very similar properties only (almost the same as an appraised one). On other end of the scope, values Kmax ∈ 〈0.75, 0.95〉 let to collect for calculations almost all properties from the prepared set. The middle interval with Kmax ∈ 〈0.50, 0.70〉 let to take into account typically similar properties. The edge of the scope were Kmax = 1 gave the opportunity to take into account all prepared set of 104 ‘sold’ properties. The only cleaning of the start set that was made in this case was the rejection of the subjects with outstanding prices.
Figure 1
Chart of the total, relative assessment (TRA) of the estimation accuracy according to the imposed criteria parameters Kmax and Kcorrmin (22)
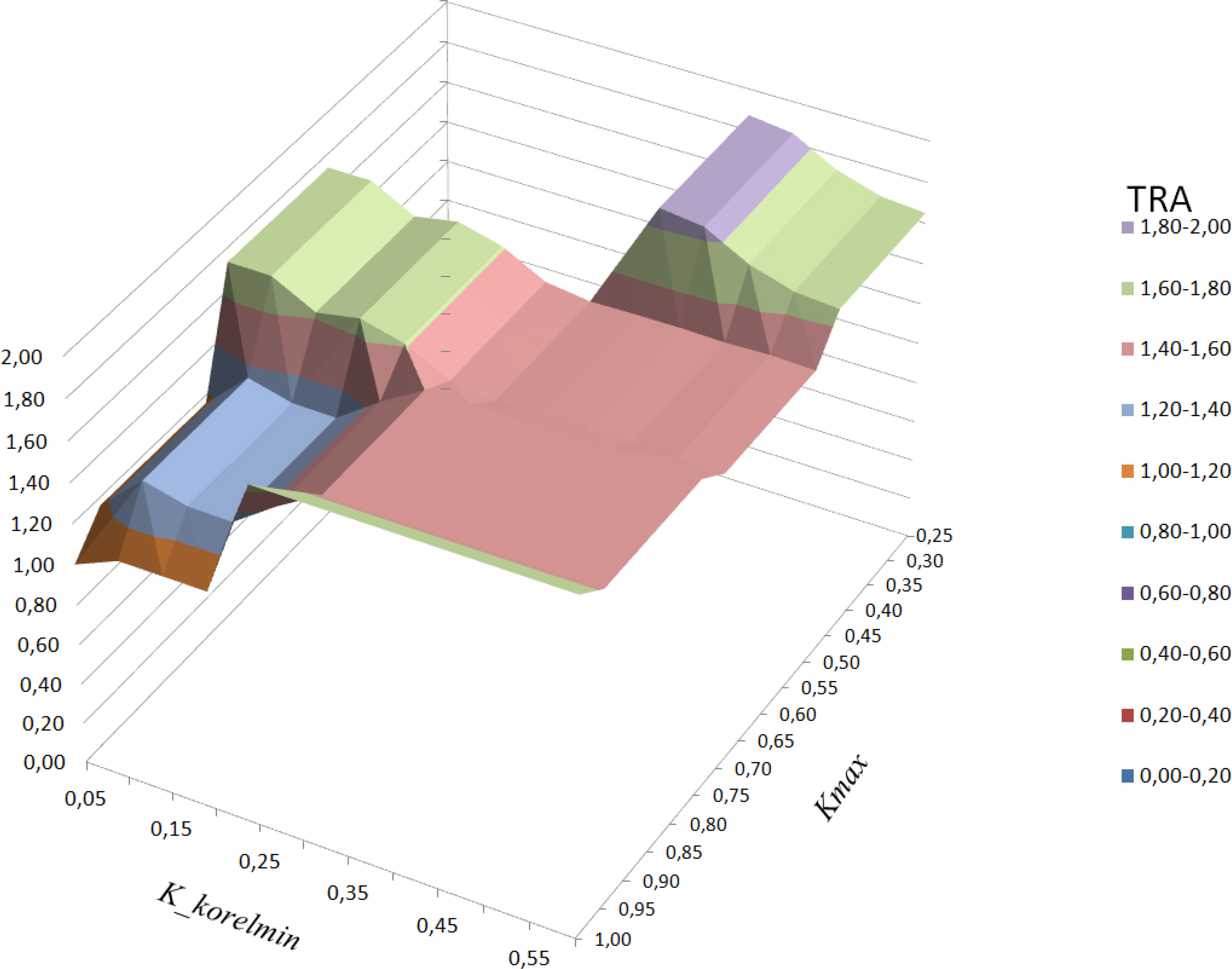
Next, the selection of significant variables, in each case of calculation, was performed. Each case of Kmax included a separate calculation with Kcorrmin parameter varying from 0.05 to 0.6. Kcorrmin was a criterion factor affecting the accepted minimum significance. Kcorrmin ∈ 〈0.05, 0.25〉 gave a very weak criterion for the rejection of variables (a case formally unacceptable from statistical point of view) and allowed the algorithm to accept all or almost all initially prepared variables. A weak correlation between vectors A〈j〉 and YA (Kcorrmin ∈ 〈0.30, 0.35t〉) sometimes caused the rejections of some variables as not significant, while in case of Kcorrmin ∈ 〈0.40, 0.60〉, most of variable were rejected. Therefore, calculations with Kcorrmin > 0.60 (most wanted from a technological point of view) gave no advantages in the performed research.
Due to the huge number of single calculations, as well as final results, it was decided to show them in the aggregated way. Each single experiment gave as a result the estimation
The matrix of such proportional and aggregated results is shown in Table 1 and Figure 1 respectively.
Table 1
Total, relative assessment (TRA) of the estimation accuracy according to the imposed criteria parameters Kmax and Kcorrmin (22)
. Experiment results and conclusions
It was shown that nominally, the best aggregated results of accuracy (proportional cumulated accuracy factor equals 1) are obtained with configuration { Kmax = 1|Kcorrmin = 0.05 }. The next minimal aggregated results have occurred for the configuration }Kmax = 1|Kcorrmin ∈ 〈0.0.10, 0.20〉 } when the result is 1.0913 and Kmax ∈ 〈0.75, 0.95〉|Kcorrmin = 0.05 } with result equal 1.1612. Within the range of coefficients discussed above, one can also find another slight, local minimum (1.2985). All of that means that all (or almost all) data initially collected in the set (YA, A) can be used in each discussed calculation. Moreover, the numbers in Table 1 as well as the chart, show that while Kmax is greater than 0.7 – the stronger a correlation remand is, the worst value estimations can be obtained. In other words, this conclusion could mean that there is no need to respect any similarity issues as well as a signification problem of independent variables. But it is not true. Skipping this unacceptable proposal, one can also find that within the rest of possible configurations of Kmax and Kcorrmin different conclusions are also to be drawn. For ranges of Kmax ∈ 〈0.25, 0.45〉 as well as Kmax ∈ 〈0.50, 0.70〉, the relationship between proportional, aggregated results of estimation accuracy and the criterion factor Kcorrmin indicates the opposite tendency: better result of accuracy can be obtained when the correlation demand arises.
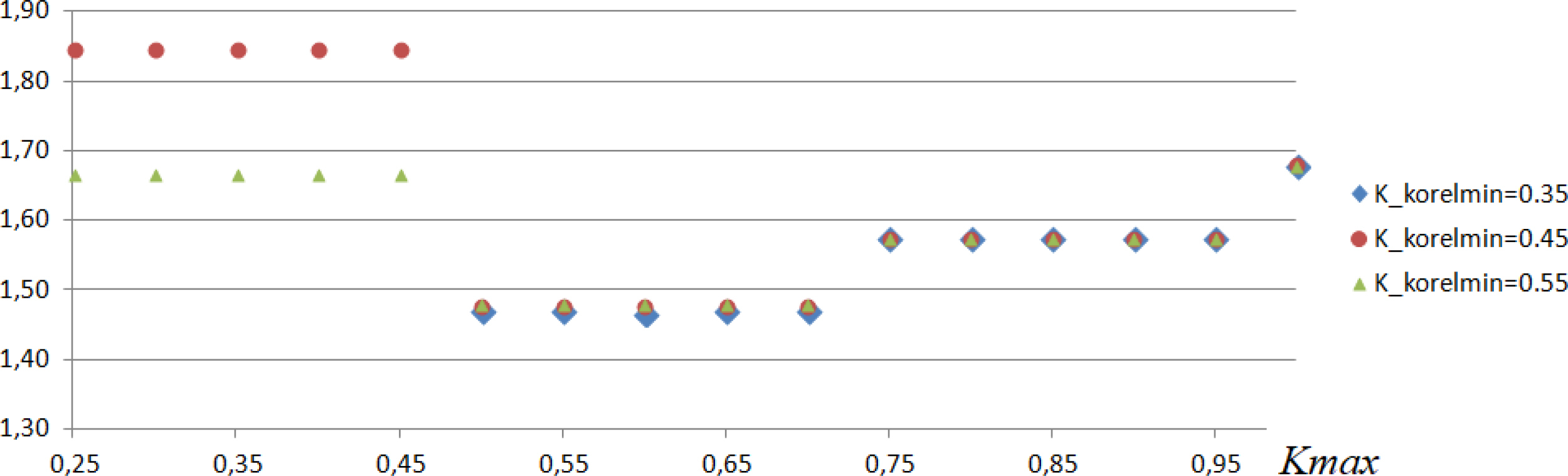
The most interesting result of the above investigation is that when the criterion of the demand of correlation level between vectors A〈j〉 and YA is medium or strong (Kcorrmin ≥ 0.30), then the similarity issue starts to be significant. It is to be noticed that in each column in Table 1, when Kcorrmin ≥ 0.30, or in each corresponding cross-section (Figure 2) of the surface chart on Figure 1, the total, relative assessment (TRA) of accuracy is the lowest for medium range of Kmax (Kmax ∈ 〈0.50, 0.70〉). Moreover, within this range, it has its local minimum equal 1.4672 for Kmax = 0.60 and Kcorrmin = 0.354, telling that the most accurate estimations (in the sense of (14)) were obtained when the criterion of dissimilarity (21) was strong enough (Kmax = 0.60) and the demand of correlation level of independent variable was in the medium range. Each extreme demand on similarity of comparables or signification of descriptive variables acted against the effectiveness of estimations process as well as against the estimation accuracy.
Figure 2
The cross-sections of the surface chart of TRA at selected lines of Kcorrmin. Notice that for Kcorrmin < 0.40 no numerical results were obtained.
These considerations and the results of the experiment show that, in the estimation process based on a linear price model and being resolved by n the LS method, there are some conditions not considered yet which may affect the prediction relevance of endogenous variable. The essence of these conditions is contained in the relationship between the characteristics of the subjects taken into the analysis. In the conducted experiment, the role of the endogenous variable has been assigned as the unit price of a hypothetical property. The starting point for the conducted considerations was the real estate market, since the prediction quality and its reliability are specifically conditioned by the question of similarity on that market. The carried out studies demonstrate that the link between the similarity (or dissimilarity) of the sold properties, used as comparables and the valued property, affects the undertaken estimations’ accuracy. The observations made show that there is a niche that is worthy of further research.
